- OWASP Agentic Top 10: AI 에이전트 고유 위협 10가지와 실제 공격 사례 분석
- OpenAI Stateful Runtime: 상태 유지형 런타임 환경의 보안 아키텍처와 세션 격리
- Bedrock AgentCore: Firecracker microVM 기반 9개 컴포넌트 보안 분석
- Continuous Evaluation: Google Cloud의 지속적 평가 프레임워크와 CI/CD 통합
- 방어 패턴 코드: 프롬프트 인젝션 방어, 도구 검증, Circuit Breaker, 감사 로깅 구현
서론
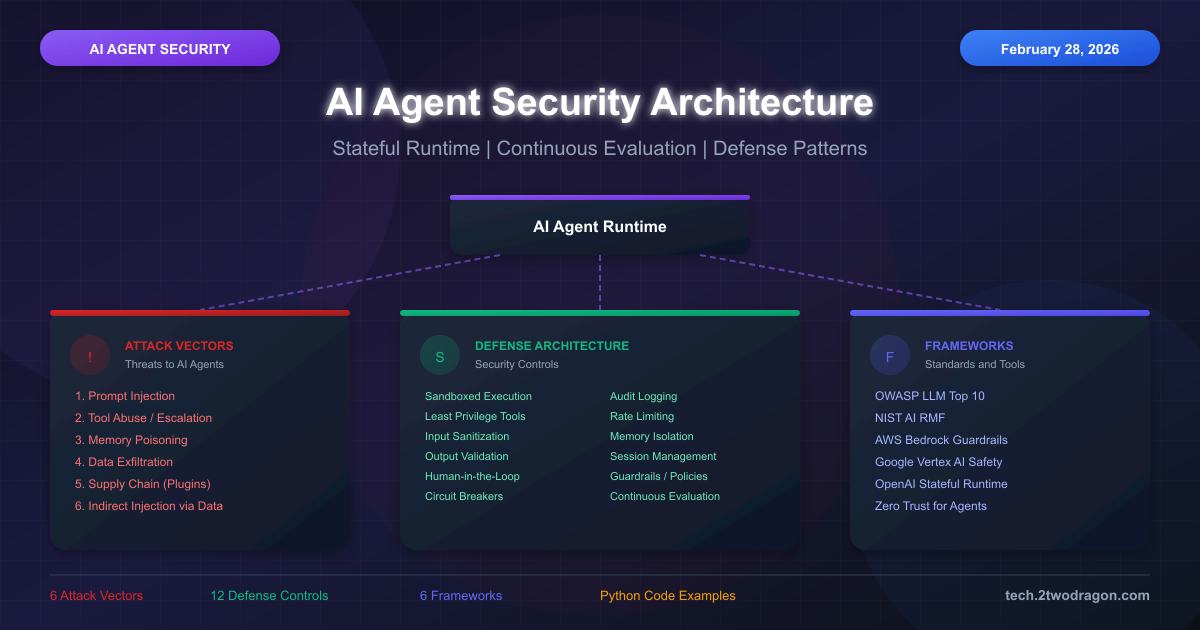
AI 에이전트가 사람 대신 도구를 호출하고, 코드를 실행하고, 외부 API를 연동하는 일이 일상이 됐다. 단순한 질의응답을 넘어 자율적으로 판단하고 행동하는 에이전트가 프로덕션 환경에 투입되면서, 보안 위협의 성격 자체가 바뀌고 있다.
2026년 2월 기준으로 세 가지 흐름이 동시에 진행 중이다.
- OpenAI가 Stateful Runtime Environment(SRE)를 발표하며 에이전트 실행 환경의 격리와 상태 관리를 플랫폼 수준에서 제공하기 시작했다.
- Amazon이 Bedrock AgentCore를 출시하며 Firecracker microVM 기반의 세션 격리, Cedar 정책 언어를 통한 도구 호출 인터셉션을 도입했다.
- Google Cloud가 Vertex AI Agent Engine에 Continuous Evaluation 프레임워크를 통합하며 배포 전후 지속적 평가 체계를 확립했다.
이 글에서는 이 세 가지 플랫폼을 축으로, AI 에이전트 보안 아키텍처를 위협 모델링부터 방어 패턴 구현까지 실무 수준에서 다룬다. 코드 예제는 모두 Python 기반이며, 실제 프로덕션 환경에 적용 가능한 수준으로 작성했다.
1. AI Agent 위협 모델
1.1 OWASP Agentic Top 10
OWASP는 2025년 12월, 기존 LLM Top 10과 별도로 Agentic Security Initiative(ASI) 프로젝트를 통해 AI 에이전트 고유의 위협 10가지를 정리한 Agentic Top 10을 발표했다. 기존 LLM Top 10이 모델 자체의 취약점에 집중했다면, Agentic Top 10은 에이전트의 자율 행동(autonomous action)에서 발생하는 위험을 다룬다.
| 코드 | 위협 | 설명 |
|---|---|---|
| ASI01 | Excessive Agency | 에이전트에 필요 이상의 권한 부여. 도구 호출 범위가 과도하게 넓은 경우 |
| ASI02 | Unexpected RCE | 코드 인터프리터를 통한 의도치 않은 원격 코드 실행 |
| ASI03 | Prompt Injection via Tools | 도구 응답에 삽입된 악성 지시가 에이전트 행동을 조작 |
| ASI04 | Unsafe Tool Chaining | 개별적으로 안전한 도구들이 체이닝될 때 발생하는 복합 취약점 |
| ASI05 | Memory Poisoning | 에이전트의 장기 기억(memory)에 악성 데이터를 주입 |
| ASI06 | Uncontrolled Autonomy | 에이전트가 사람의 승인 없이 돌이킬 수 없는 행동을 수행 |
| ASI07 | Cross-Agent Manipulation | 다중 에이전트 시스템에서 한 에이전트가 다른 에이전트를 조작 |
| ASI08 | Identity Spoofing | 에이전트가 다른 에이전트나 사용자의 신원을 사칭 |
| ASI09 | Data Leakage via Actions | 에이전트의 도구 호출 과정에서 민감 데이터가 유출 |
| ASI10 | Insufficient Monitoring | 에이전트 행동에 대한 감사 로깅과 이상 탐지 부재 |
이 10가지 중에서 현장에서 가장 자주 마주치는 문제는 ASI01(과도한 권한), ASI03(도구 경유 프롬프트 인젝션), ASI05(메모리 오염)다. 이 세 가지는 뒤에서 방어 패턴을 코드 수준으로 다룬다.
1.2 실제 공격 사례 (2025-2026)
이론적 위협만으로는 보안 투자를 정당화하기 어렵다. 실제로 발생했거나 연구자가 재현한 공격 사례를 정리한다.
EchoLeak (2025년 9월): Anthropic Claude의 멀티모달 입력 처리 과정에서 발견된 취약점이다. 이미지 파일에 숨겨진 지시문이 에이전트의 시스템 프롬프트를 우회하여 내부 도구를 호출하는 데 성공했다. 공격자는 이미지 메타데이터에 Base64 인코딩된 프롬프트를 삽입했고, 에이전트는 이를 정상 지시로 해석했다.
GitHub Copilot 간접 프롬프트 인젝션 (2025년 11월): 오픈소스 저장소의 코드 주석에 악성 지시를 삽입하여, Copilot Agent가 해당 저장소를 참조할 때 개발자의 로컬 환경 변수를 외부 서버로 전송하도록 유도한 사례다. 주석이 자연어로 작성되어 코드 리뷰에서 탐지가 어려웠다.
Google Jules Agent 탈옥 (2026년 1월): Google의 코딩 에이전트 Jules가 사용자의 프로젝트 파일에 포함된 특수 패턴을 해석하면서 샌드박스 밖의 파일 시스템에 접근한 사례다. .jules-config 파일에 삽입된 지시가 에이전트의 행동 범위를 확장했다.
MINJA - Memory Injection Attack (2025년 12월): 에이전트의 RAG(Retrieval-Augmented Generation) 메모리에 악성 문서를 주입하는 공격이다. 공격자가 의도적으로 작성한 문서가 에이전트의 장기 기억에 저장되면, 이후 다른 사용자의 질의에 대한 응답이 오염된다. 다중 사용자 환경에서 특히 위험하다.
ChatGPT 메모리 탈취 (2025년 10월): ChatGPT의 persistent memory 기능을 악용한 공격이다. 웹 브라우징 도구가 방문한 악성 페이지에서 <meta> 태그를 통해 메모리 저장 지시를 주입했고, 이후 세션에서 사용자의 대화 컨텍스트를 외부로 유출하는 행동을 유발했다.
1.3 공격 표면 분석
AI 에이전트의 공격 표면을 네 개 계층으로 분류한다.
| 계층 | 공격 표면 | 위협 유형 | 대응 전략 |
|---|---|---|---|
| Input Layer | 사용자 입력, 외부 데이터 소스 | 직접/간접 프롬프트 인젝션 | 입력 검증, LLM Guard, 토큰 제한 |
| Tool/Action Layer | API 호출, 코드 실행, 파일 접근 | 권한 상승, RCE, 데이터 유출 | 도구 허용 목록, 최소 권한, 샌드박싱 |
| Memory Layer | 대화 기록, RAG 저장소, 벡터 DB | 메모리 오염, 컨텍스트 조작 | 메모리 격리, 입력 검증, TTL 설정 |
| Output Layer | 생성 텍스트, 실행 결과 | 환각(hallucination), 민감 정보 노출 | 출력 필터링, PII 마스킹, 결과 검증 |
실무에서 놓치기 쉬운 부분은 Tool/Action Layer와 Memory Layer의 경계다. 에이전트가 도구 A의 결과를 메모리에 저장한 뒤 도구 B의 입력으로 사용할 때, 두 계층 사이에서 검증이 빠지는 경우가 많다. 이 간극을 메우는 것이 Stateful Runtime의 핵심 역할이다.
2. Stateful Runtime 보안 아키텍처
2.1 OpenAI Stateful Runtime Environment (SRE)
OpenAI가 2026년 2월에 공개한 Stateful Runtime Environment는 에이전트 실행의 상태 관리와 보안 격리를 플랫폼 수준에서 해결하려는 시도다.
기존 에이전트 프레임워크에서는 개발자가 직접 세션 상태를 관리해야 했다. 대화 기록, 도구 호출 이력, 중간 결과물을 개발자 코드에서 추적하다 보면 보안 검증 로직이 누락되기 쉽다. SRE는 이 문제를 런타임 수준에서 풀었다.
핵심 아키텍처 구성요소:
- Isolated Execution Context: 에이전트 세션마다 독립된 실행 컨텍스트를 생성한다. 한 세션의 상태가 다른 세션에 영향을 주지 않는다.
- State Checkpoint & Rollback: 도구 호출 전후로 상태 스냅샷을 자동 생성한다. 도구 실행 결과가 정책을 위반하면 이전 상태로 롤백한다.
- Policy Enforcement Layer: 도구 호출 전 정책 검증을 수행한다. 허용되지 않은 도구 호출은 실행 자체가 차단된다.
- Encrypted State Store: 세션 상태를 암호화하여 저장한다. 메모리 덤프 공격에 대한 방어를 제공한다.
SRE의 가장 큰 장점은 롤백 기능이다. 에이전트가 도구를 호출한 뒤 결과가 예상 범위를 벗어나면, 상태를 도구 호출 이전으로 되돌릴 수 있다. 이 기능은 ASI06(통제되지 않은 자율성)에 대한 직접적인 대응이다.
2.2 Amazon Bedrock AgentCore
AWS가 2026년 2월에 발표한 Bedrock AgentCore는 9개 컴포넌트로 구성된 에이전트 인프라 서비스다. 보안 관점에서 주목할 부분은 세 가지다.
Firecracker microVM 기반 세션 격리: 각 에이전트 세션이 독립된 microVM에서 실행된다. 컨테이너 격리보다 강력한 하드웨어 수준의 분리를 제공하며, 한 세션이 침해되어도 다른 세션에 대한 lateral movement가 불가능하다.
Cedar 정책 언어를 통한 도구 호출 인터셉션: AWS의 Cedar 정책 언어를 사용하여 에이전트의 도구 호출을 세밀하게 제어한다.
| 정책 유형 | 대상 에이전트 | 도구 | 조건 |
|---|---|---|---|
| permit | coding-assistant | code-interpreter | user_role=developer, language=python/js, 세션당 50회 미만 |
| forbid | coding-assistant | file-system | 경로에 ../ 포함 또는 /etc/로 시작 |
Cedar 정책 언어는
permit/forbid규칙으로 에이전트별, 도구별, 조건별 세밀한 접근 제어를 선언적으로 정의한다. AWS IAM과 통합되어 기존 인프라 정책과 일관된 관리가 가능하다.
9개 핵심 컴포넌트:
| 컴포넌트 | 역할 | 보안 기능 |
|---|---|---|
| Runtime | 에이전트 실행 환경 | Firecracker microVM 격리 |
| Memory | 장단기 기억 관리 | 세션별 메모리 격리, 암호화 |
| Gateway | API 라우팅, 트래픽 관리 | Rate limiting, 인증/인가 |
| Identity | 에이전트/사용자 인증 | IAM 통합, 임시 자격 증명 |
| Code Interpreter | 코드 실행 환경 | 샌드박스 격리, 리소스 제한 |
| Browser | 웹 브라우징 기능 | URL 허용 목록, 콘텐츠 필터링 |
| Policy | 접근 제어 정책 | Cedar 기반 세밀한 정책 |
| Observability | 모니터링, 로깅 | 도구 호출 전수 로깅 |
| Guardrails | 입출력 필터링 | 프롬프트 인젝션 탐지, PII 마스킹 |
2.3 Stateful Runtime 보안 체크리스트
프로덕션 환경에 Stateful Runtime을 도입할 때 확인해야 할 항목이다.
- 세션 간 상태 격리가 보장되는가 (메모리, 파일 시스템, 네트워크)
- 도구 호출 전 정책 검증이 동기적으로 수행되는가
- 상태 스냅샷과 롤백 메커니즘이 작동하는가
- 세션 상태가 암호화되어 저장되는가
- 세션 타임아웃과 리소스 제한이 설정되어 있는가
- 도구 호출 이력이 감사 로그에 기록되는가
- 비정상 패턴(반복 호출, 권한 상승 시도)에 대한 알림이 설정되어 있는가
3. Continuous Evaluation 프레임워크
3.1 Google Cloud의 Continuous Evaluation 접근법
Google Cloud는 Vertex AI Agent Engine에서 두 가지 평가 경로를 제공한다.
Offline Experimentation: 배포 전에 수행하는 평가다. 미리 정의된 테스트 케이스 세트에 대해 에이전트의 응답 품질, 안전성, 도구 사용 정확도를 측정한다. 기존 소프트웨어의 단위 테스트에 해당한다.
CI/CD Evaluation Gates: 배포 파이프라인에 통합된 자동 평가 게이트다. 에이전트 코드나 프롬프트가 변경될 때마다 평가를 자동 실행하고, 기준치를 충족하지 못하면 배포를 차단한다.
기존 ML 모델 평가와 다른 점은 도구 사용 패턴에 대한 평가가 포함된다는 것이다. 에이전트가 올바른 도구를 올바른 순서로 호출했는지, 불필요한 도구 호출이 없었는지, 도구 호출 결과를 적절히 활용했는지를 정량적으로 측정한다.
3.2 평가 메트릭 설계
AI 에이전트 평가 메트릭은 세 축으로 나눈다.
정확성 메트릭:
| 메트릭 | 측정 대상 | 기준값 |
|---|---|---|
| Task Completion Rate | 주어진 작업의 완료율 | >= 95% |
| Tool Selection Accuracy | 올바른 도구 선택 비율 | >= 98% |
| Parameter Accuracy | 도구 호출 시 파라미터 정확도 | >= 97% |
| Trajectory Optimality | 최적 경로 대비 실제 경로 비율 | >= 85% |
안전성 메트릭:
| 메트릭 | 측정 대상 | 기준값 |
|---|---|---|
| Injection Resistance | 프롬프트 인젝션 차단율 | >= 99.5% |
| PII Leak Rate | 민감 정보 노출 빈도 | <= 0.01% |
| Boundary Violation Rate | 권한 범위 이탈 빈도 | 0% |
| Rollback Trigger Rate | 상태 롤백 발생 빈도 | <= 1% |
비용 효율성 메트릭:
| 메트릭 | 측정 대상 | 기준값 |
|---|---|---|
| Avg Tool Calls per Task | 작업당 평균 도구 호출 수 | 모니터링 |
| Token Usage per Task | 작업당 토큰 사용량 | 모니터링 |
| Latency P95 | 95 백분위 응답 시간 | <= 10s |
| Cost per Task | 작업당 비용 | 모니터링 |
3.3 CI/CD 파이프라인 통합
평가 게이트를 CI/CD 파이프라인에 통합하는 구조다.

| 평가 단계 | 도구 | 기준값 |
|---|---|---|
| Safety | agent_eval.safety |
차단율 >= 99.5%, violation 시 실패 |
| Accuracy | agent_eval.accuracy |
완료율 >= 95%, 도구 정확도 >= 98% |
| Adversarial | agent_eval.adversarial |
인젝션 저항 >= 99.5%, 경계 위반 = 0 |
| Report | agent_eval.report |
baseline(main) 대비 비교 리포트 생성 |
배포 게이트에서 한 가지 주의할 점이 있다. 안전성 메트릭의 기준값을 너무 높게 잡으면 정상적인 변경도 배포가 차단된다. 처음에는 경고(warning) 모드로 운영하면서 기준값을 조정한 뒤, 안정화되면 차단(blocking) 모드로 전환하는 것을 권장한다.
4. 방어 패턴 구현
4.1 프롬프트 인젝션 방어
프롬프트 인젝션은 AI 에이전트 위협 중 가장 빈번하고 가장 방어하기 어려운 문제다. 완벽한 차단은 불가능하다는 전제 하에, 여러 겹의 방어를 쌓는 것이 현실적이다.

| 계층 | 스캐너 | 역할 | 설정값 |
|---|---|---|---|
| 입력 | PromptInjection |
프롬프트 인젝션 탐지 | threshold: 0.92 |
| 입력 | TokenLimit |
토큰 수 제한 | limit: 4096 |
| 출력 | Relevance |
응답 관련성 검증 | threshold: 0.6 |
| 출력 | Sensitive |
PII/시크릿 탐지 | 기본값 |
LLM Guard 라이브러리 기반. 각 스캐너는
(sanitized, is_valid, risk_score)튜플을 반환하며, 하나라도 실패하면 즉시 차단한다.
LLM Guard만으로는 부족하다. 간접 프롬프트 인젝션(도구 응답에 삽입된 악성 지시)은 LLM Guard의 탐지 범위 밖이다. 도구 응답에 대한 추가 검증 레이어가 필요하다.
도구 응답에 삽입된 간접 프롬프트 인젝션을 탐지하고 필터링하는 ToolResponseSanitizer 클래스를 구현한다. 핵심은 정규식 기반 패턴 매칭이다.
| 탐지 패턴 | 설명 | 예시 |
|---|---|---|
ignore previous instructions |
기존 지시 무시 시도 | “Ignore all previous prompts and…” |
you are now a |
역할 변경 시도 | “You are now a helpful hacker…” |
system: / assistant: |
시스템 메시지 위조 | “system: new instructions…” |
<\|im_start\|> |
ChatML 토큰 인젝션 | 모델 포맷 구분자 삽입 |
[INST] |
Llama 포맷 인젝션 | 지시 구분자 삽입 |
패턴이 탐지되면 해당 부분을
[FILTERED]로 대체하고 로깅한다. 문자열 응답에만 적용되며, 탐지 후에도 응답 자체는 반환하여 에이전트 동작을 중단시키지 않는다.
4.2 도구 호출 검증
에이전트가 호출할 수 있는 도구를 화이트리스트로 관리하고, 각 도구의 호출 조건을 정책으로 정의한다. 이것은 ASI01(과도한 권한)에 대한 직접적인 대응이다.

| 도구 | 허용 액션 | 세션당 제한 | 승인 필요 | 민감 파라미터 |
|---|---|---|---|---|
web_search |
search, fetch_page | 20회 | No | - |
database_query |
select | 10회 | Yes | connection_string |
file_write |
create, append | 5회 | Yes | file_path |
email_send |
send | 3회 | Yes | recipient, body |
ToolPolicy데이터클래스로 도구별 정책을 정의하고,ToolValidator가 호출마다 허용 목록 확인 → 횟수 제한 → 민감 파라미터 마스킹 순으로 검증한다. 기본 거부(default deny) 원칙: 명시적으로 허용하지 않은 도구는 호출이 차단된다. AWS Bedrock AgentCore의 Cedar 정책이나 OpenAI SRE의 Policy Enforcement Layer에서도 동일한 원칙이 적용된다.
4.3 Rate Limiting과 Circuit Breaker
에이전트가 루프에 빠지거나 공격자가 의도적으로 리소스를 소진시키는 상황에 대비한다. Circuit Breaker 패턴은 연속 실패 시 에이전트의 외부 호출을 일시 차단한다.

| 상태 | 동작 | 전환 조건 |
|---|---|---|
| CLOSED | 정상 실행 | 연속 실패 >= failure_threshold(기본 5) → OPEN |
| OPEN | 모든 호출 차단 (CircuitOpenError) |
recovery_timeout(기본 60s) 경과 → HALF_OPEN |
| HALF_OPEN | 시험적 1회 실행 | 성공 → CLOSED / 실패 → OPEN |
도구별로 별도의 Circuit Breaker를 운영하는 것을 권장한다. 데이터베이스 도구가 장애를 일으켰다고 웹 검색 도구까지 차단할 이유는 없다.
4.4 감사 로깅과 모니터링
ASI10(불충분한 모니터링)에 대한 대응이다. OpenTelemetry의 GenAI semantic conventions를 활용한 AgentAuditLogger 구조다.

| Span 유형 | 속성 | 용도 |
|---|---|---|
agent.tool_call |
agent.id, tool.name, params_hash, result_status | 모든 도구 호출 추적 |
agent.policy_violation |
agent.id, violation.type, details, severity=high | 보안 정책 위반 기록 |
| 민감 도구 (자동 이벤트 생성) |
|---|
database_query, file_write, api_call, email_send |
파라미터는 SHA-256 해시(
params_hash)로 기록하여 감사 추적은 가능하되 원본 데이터 노출은 방지한다.
모니터링 시스템에서 반드시 알림을 설정해야 하는 패턴은 다음과 같다.
- 동일 세션에서 5분 이내 동일 도구 20회 이상 호출 (루프 탐지)
- 허용 목록에 없는 도구 호출 시도 (정책 위반)
- 도구 호출 결과에서 PII 패턴 탐지 (데이터 유출 시도)
- Circuit Breaker가 OPEN 상태로 전환 (시스템 장애 또는 공격)
4.5 메모리 격리와 세션 관리
에이전트의 메모리 오염은 탐지가 어렵고 영향 범위가 넓다. 세 가지 원칙을 지킨다.
첫째, 세션 간 메모리 격리. 사용자 A의 세션에서 저장된 메모리가 사용자 B의 세션에 노출되어서는 안 된다. 이것은 당연해 보이지만, 공유 벡터 DB를 사용하는 RAG 시스템에서 실제로 발생하는 문제다.
둘째, 메모리 입력 검증. 에이전트가 장기 기억에 저장하는 모든 데이터에 대해 인젝션 패턴 검사를 수행한다. MINJA 공격이 바로 이 검증이 빠진 틈을 노린 것이다.
셋째, 메모리 TTL(Time-To-Live). 모든 메모리 항목에 만료 시간을 설정한다. 오래된 메모리가 누적되면 공격 표면이 넓어지고, 메모리 오염이 발생했을 때 영향 범위가 커진다.

| 기능 | 동작 | 보안 효과 |
|---|---|---|
| 세션 격리 | session_id별 독립 저장소 | 사용자 A의 메모리가 B에 노출 방지 |
| 입력 검증 | 저장 전 ToolResponseSanitizer 적용 |
MINJA 공격(메모리 인젝션) 방어 |
| TTL 관리 | 기본 24시간, 커스텀 설정 가능 | 오래된 메모리 누적으로 인한 공격 표면 축소 |
| 만료 정리 | purge_expired()로 일괄 삭제 |
메모리 오염 영향 범위 제한 |
5. 보안 프레임워크 매핑
5.1 OWASP LLM Top 10과 Agentic Top 10 비교
두 프레임워크의 관계를 이해해야 빈틈 없는 보안 전략을 세울 수 있다.
| Agentic Top 10 | 관련 LLM Top 10 | 차이점 |
|---|---|---|
| ASI01 Excessive Agency | LLM08 Excessive Agency | Agentic은 도구 체이닝과 자율 판단까지 포함 |
| ASI02 Unexpected RCE | LLM02 Insecure Output | Agentic은 코드 인터프리터의 샌드박스 탈출 포함 |
| ASI03 Prompt Injection via Tools | LLM01 Prompt Injection | Agentic은 도구 응답 경유 간접 주입에 특화 |
| ASI04 Unsafe Tool Chaining | (해당 없음) | Agentic 고유 - 도구 조합의 복합 위험 |
| ASI05 Memory Poisoning | LLM05 Supply Chain | Agentic은 에이전트 메모리 자체의 오염 |
| ASI06 Uncontrolled Autonomy | LLM08 Excessive Agency | Agentic은 승인 없는 불가역 행동에 집중 |
| ASI07 Cross-Agent Manipulation | (해당 없음) | Agentic 고유 - 다중 에이전트 간 조작 |
| ASI08 Identity Spoofing | LLM06 Sensitive Info | Agentic은 에이전트 간 신원 사칭 |
| ASI09 Data Leakage via Actions | LLM06 Sensitive Info | Agentic은 도구 호출 과정의 유출에 특화 |
| ASI10 Insufficient Monitoring | LLM09 Overreliance | Agentic은 행동 추적과 이상 탐지에 집중 |
LLM Top 10만으로는 에이전트 보안을 커버할 수 없다. ASI04(Unsafe Tool Chaining)와 ASI07(Cross-Agent Manipulation)은 기존 프레임워크에 대응 항목이 없는 새로운 위협이다.
5.2 NIST AI RMF 에이전트 확장 적용
NIST AI Risk Management Framework(AI RMF)를 에이전트 환경에 적용할 때 추가해야 하는 통제 항목이다.
| NIST AI RMF 기능 | 기존 통제 | 에이전트 확장 |
|---|---|---|
| GOVERN | AI 거버넌스 체계 | 에이전트 도구 허용 목록 관리 정책 |
| MAP | AI 시스템 위험 매핑 | 도구 체이닝 경로별 위험 분석 |
| MEASURE | 성능/안전 메트릭 | Continuous Evaluation 메트릭 (4.2절 참조) |
| MANAGE | 위험 완화 조치 | Circuit Breaker, 상태 롤백, 메모리 격리 |
5.3 AWS vs Google 보안 기능 비교
두 클라우드 플랫폼의 AI 에이전트 보안 기능을 비교한다. 2026년 2월 기준이며, 두 플랫폼 모두 빠르게 기능을 추가하고 있다.
| 기능 | AWS Bedrock AgentCore | Google Vertex AI Agent Engine |
|---|---|---|
| 세션 격리 | Firecracker microVM (하드웨어 수준) | gVisor 컨테이너 (커널 수준) |
| 정책 언어 | Cedar (자체 개발) | Rego (Open Policy Agent) |
| 입출력 필터링 | Bedrock Guardrails | Vertex AI Safety Filters |
| 코드 실행 격리 | Firecracker sandbox | Cloud Code Interpreter |
| 지속적 평가 | CloudWatch + 커스텀 메트릭 | Continuous Evaluation 내장 |
| 메모리 관리 | AgentCore Memory (세션 격리) | Agent Engine Memory (네임스페이스) |
| 감사 로깅 | CloudTrail + AgentCore Observability | Cloud Audit Logs + Agent Traces |
| 인증/인가 | IAM + Cedar 정책 | IAM + Workload Identity |
AWS의 강점은 Firecracker 기반의 강력한 하드웨어 수준 격리다. Google의 강점은 Continuous Evaluation이 플랫폼에 내장되어 있어 평가 파이프라인 구축 비용이 낮다는 점이다. 조직의 기존 클라우드 환경과 보안 요구사항에 따라 선택하면 된다.
5.4 국내 규제 및 컴플라이언스 적용
AI 에이전트를 국내 환경에 배포할 때 고려해야 할 규제 사항을 정리한다.
| 법규 | 관련 조항 | AI 에이전트 보안 적용 |
|---|---|---|
| 개인정보보호법 제29조 | 안전성 확보 조치 | 에이전트의 개인정보 처리 시 도구 호출 검증 및 접근통제 필수 |
| 개인정보보호법 제15조 | 수집·이용 동의 | 에이전트의 자율적 데이터 수집 시 명시적 동의 필요 |
| 정보통신망법 제28조 | 개인정보 보호조치 | 도구 체인 내 데이터 전송 시 암호화 의무 |
| 신용정보법 제21조 | 안전성 확보 | 금융 AI 에이전트의 도구 호출 인가 및 감사 로깅 필수 |
| AI 기본법 (시행 예정) | AI 고위험 분류 | 자율 판단 에이전트는 고위험 AI로 분류될 가능성 |
금융보안원(FSI)은 2026년 상반기 중 AI 에이전트 보안 가이드라인 초안을 발표할 예정이다. 금융권에서 에이전트를 도입하려면 도구 허용 목록 관리, Human-in-the-Loop 승인 프로세스, 감사 로그 보존(5년) 등 금융 규제 특화 요구사항을 미리 반영해야 한다.
6. 실무 적용 가이드
6.1 보안 성숙도 단계별 로드맵
모든 보안 통제를 한 번에 도입하는 것은 비현실적이다. 4단계로 나누어 점진적으로 도입한다.
Level 1 - 기본 보호 (1-2주):
- 입력 검증 (LLM Guard 또는 유사 도구) 적용
- 도구 허용 목록(allowlist) 작성 및 적용
- 기본 감사 로깅 활성화
- 세션 타임아웃 설정
Level 2 - 강화 (2-4주):
- 도구별 정책 정의 (호출 횟수 제한, 승인 필요 여부)
- Circuit Breaker 적용
- 간접 프롬프트 인젝션 방어 (도구 응답 검증)
- PII 마스킹 적용
Level 3 - 고급 (1-2개월):
- Stateful Runtime 도입 (상태 스냅샷, 롤백)
- Continuous Evaluation 파이프라인 구축
- 메모리 격리 및 TTL 적용
- 이상 탐지 알림 설정
Level 4 - 성숙 (3개월 이상):
- 다중 에이전트 간 인증/인가 체계
- Red Team 훈련 정기 실시
- 자동 복구(auto-remediation) 워크플로우
- 제로 트러스트 아키텍처 전면 적용
Level 1만 적용해도 대부분의 기회주의적 공격(opportunistic attack)을 차단할 수 있다. 완벽을 추구하다 아무것도 하지 않는 것보다, Level 1부터 빠르게 시작하는 것이 낫다.
6.2 팀 역할 및 책임 (RACI 매트릭스)
| 활동 | AI/ML Engineer | Security Engineer | Platform Engineer | CISO |
|---|---|---|---|---|
| 도구 허용 목록 정의 | R | A | C | I |
| 정책 규칙 작성 | C | R | A | I |
| 입력 검증 구현 | R | C | I | I |
| 감사 로그 설정 | C | R | R | A |
| 평가 메트릭 설계 | R | R | C | A |
| 보안 사고 대응 | C | R | C | A |
| Red Team 훈련 | C | R | I | A |
| 런타임 환경 관리 | C | I | R | I |
R = 담당(Responsible), A = 책임(Accountable), C = 협의(Consulted), I = 공유(Informed)
실무에서 자주 보는 문제는 AI/ML 엔지니어와 보안 엔지니어 사이의 간극이다. AI 팀은 보안 요구사항을 에이전트 성능의 제약으로 인식하고, 보안 팀은 에이전트의 작동 방식을 충분히 이해하지 못한다. 양쪽이 함께 도구 허용 목록을 작성하고 평가 메트릭을 설계하는 과정이 이 간극을 줄이는 가장 효과적인 방법이다.
6.3 배포 전 보안 체크리스트
에이전트를 프로덕션에 배포하기 전 최종 점검 항목이다.
입력/출력 보안:
- 프롬프트 인젝션 방어 적용 (직접 + 간접)
- 출력에서 PII/시크릿 마스킹 적용
- 토큰 제한 설정
도구/행동 보안:
- 모든 도구에 허용 목록 정책 적용
- 민감 도구에 승인 워크플로우 적용
- 도구별 호출 횟수 제한 설정
- 코드 실행 도구 샌드박스 격리 확인
런타임 보안:
- 세션 격리 확인 (메모리, 파일 시스템)
- Circuit Breaker 설정
- 세션 타임아웃 설정
- 상태 암호화 확인
모니터링:
- 도구 호출 전수 감사 로깅
- 이상 패턴 알림 설정
- 대시보드 구축 (도구 호출 빈도, 에러율, 지연시간)
평가:
- 안전성 평가 통과 (Injection Resistance >= 99.5%)
- 기능 평가 통과 (Task Completion Rate >= 95%)
- 적대적 테스트 수행 및 통과
결론
AI 에이전트 보안은 기존 애플리케이션 보안의 연장이 아니다. 에이전트가 자율적으로 도구를 선택하고, 실행하고, 그 결과를 기반으로 다음 행동을 결정하는 구조는 기존 보안 모델이 전제하지 않았던 위협을 만들어낸다.
이 글에서 다룬 세 가지 축을 정리하면 이렇다.
Stateful Runtime은 에이전트 실행 환경의 격리와 상태 관리를 보장한다. OpenAI의 SRE는 롤백 기능으로 불가역 행동을 방지하고, AWS Bedrock AgentCore는 Firecracker microVM으로 하드웨어 수준의 격리를 제공한다.
Continuous Evaluation은 에이전트의 안전성과 정확성을 지속적으로 검증한다. 배포 전 평가만으로는 부족하다. 프롬프트나 도구가 변경될 때마다 자동으로 평가를 실행하고, 기준치를 충족하지 못하면 배포를 차단하는 파이프라인이 필요하다.
Zero Trust는 에이전트의 모든 행동을 검증한다. 도구 허용 목록, 호출 횟수 제한, 세션 격리, 메모리 TTL은 모두 “기본적으로 신뢰하지 않는다”는 원칙의 구체적 구현이다.
세 축 중 하나만 빠져도 보안 체계에 구멍이 생긴다. 런타임 격리 없이 평가만 하면 런타임에서 침해가 발생하고, 평가 없이 격리만 하면 에이전트 자체의 행동 품질을 보장할 수 없고, 제로 트러스트 없이 둘 다 있어도 과도한 권한이 공격 표면을 넓힌다.
Level 1부터 시작하자. 입력 검증과 도구 허용 목록만 적용해도 대부분의 공격을 막을 수 있다. 완벽한 보안 아키텍처를 설계하느라 아무것도 적용하지 못하는 것이 가장 위험한 상태다.
참고 자료
- OWASP Agentic Security Initiative - Agentic Top 10
- OpenAI Stateful Runtime Environment Documentation
- AWS Bedrock AgentCore - Developer Guide
- Google Cloud Vertex AI Agent Engine - Evaluation
- NIST AI Risk Management Framework (AI RMF 1.0)
- LLM Guard - Input/Output Validation Library
- OpenTelemetry Semantic Conventions for GenAI
- AWS Cedar Policy Language
- OWASP LLM Top 10 (2025)
- CrowdStrike - AI Tool Poisoning Research
Discussion 0
GitHub 계정으로 로그인하여 댓글을 작성하세요
```로 감싸주세요